It was inevitable that an amazing tech group like Cloudflare would eventually venture into object storage. And they’ve done so with great success when Cloudflare launched their R2 featured product which we believe enhances their overall ability to satisfy current and future customer demand in order to keep data centralized with some of their other amazing product suite of tools and infrastructure.
At DataLakeHouse.io we like to think that we are helping Cloudflare customers to further embrace the new Cloudflare R2 object storage feature for use as Data Lake Storage from which data-driven companies can build their Data LakeHouse architectures, Data Warehouses, Data Vaults, Machine Learning models and whatever fits their data fancy.
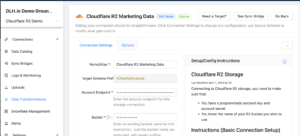
As a quick overview on the new DataLakeHouse.io and R2 integration we’ve released a quick start video integrating R2 with Snowflake through DataLakeHouse.io. There will be more to come on the setup and deep dive on how use Cloudflare R2 to build your data architectures using best-in-class concepts and architectures (like Data Vault 2.0), and tools such as DataLakeHouse.io.
After you’ve reviewed the video feel free to create an account and try out the Cloudflare R2 integration for Snowflake Cloud Data Warehouses for yourself. Reach out to our support or customer success team with any questions or for setting up a demo or technical discussion with our group of data experts.
In order to maximize the success of using Cloudflare R2 as Data Lake Storage we recommend that you understand what data you currently have in your object storage buckets that can or are desired to be used as information for analytical or other machine learning purposes. As part of the overall data strategy of structuring object storage we recommend assessing the following areas of your current object storage:
- Are your object storage buckets organized in a manner that will meet your data integration demands?
- Are you currently separating your buckets along technology or business function?
- Do you have a clean folder structure inside of each bucket which allows for cleaner loading and retrieval?
- Is the data in your object storage organized by structures, semi-structured, or binary?
- Do you currently have a good programmatic way to manage, move, and organize data if the need arised?
- Are there any current object lifecycles in place for your object storage?
- How well documented is your object storage process for ingress and egress?
We’ve found the as the needs for data to insights starts or continues to expand in the organization object storage should continually be monitored and maintained but also potentially re-focused and reorganized so that bottlenecks do not begin either for ingestion or processing of the data objects downstream.
Let us know if you’re interested on more discussions on this topic as we continue with our object storage series.